|
Mariya Hendriksen I am an intern on the Game Intelligence team at Microsoft Research Cambridge. I completed my PhD at the University of Amsterdam where I worked on multimodal machine learning for information retrieval under the supervision of Maarten de Rijke and Paul Groth. I hold a Master's degree in Artificial Intelligence from KU Leuven and a Bachelor's degree in Computational Linguistics from Novosibirsk State University. Throughout my academic journey, I've interned at several labs, including the Gemini team at Google, Bloomberg AI, Amazon Alexa, LIIR at KU Leuven, and ETH Zurich. Alongside my research, I am committed to fostering diverse and inclusive research communities. As such I serve as the General Chair for the WiML at ICML 2025, and mentor through the Inclusive AI initiative. |

|
NewsPublications
Milestones & Activities
|
Research |

|
Mariya Hendriksen, Tabish Rashid, David Bignell, Raluca Georgescu, Abdelhak Lemkhenter, Katja Hoffman, Sam Devlin*, Sarah Parisot* Under Submission, 2025 We address the challenge of automated evaluation for world model rollouts by introducing a structured protocol and UNIVERSE, a method for adapting vision-language models through unified fine-tuning to assess temporal and semantic fidelity. |

|
Maurits Bleeker*, Mariya Hendriksen*, Andrew Yates, Maarten de Rijke (co-first author) TMLR, 2024 arXiv / bibtex / Github We propose a framework to examine the shortcut learning problem in the context of Vision-Language contrastive representation learning with multiple captions per image. We show how this problem can be partially mitigated using a form of text reconstruction and implicit feature modification. |
|
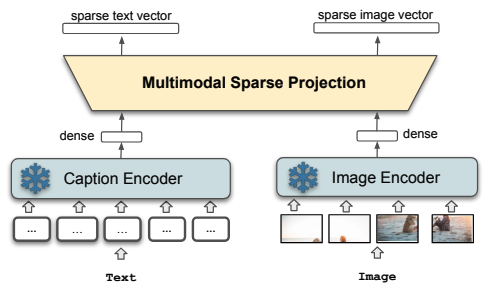
Thong Nguyen*, Mariya Hendriksen*, Andrew Yates, Maarten de Rijke (co-first author) ECIR, 2024 arXiv / Github We propose a framework for multimodal learned sparse retrieval. |
|
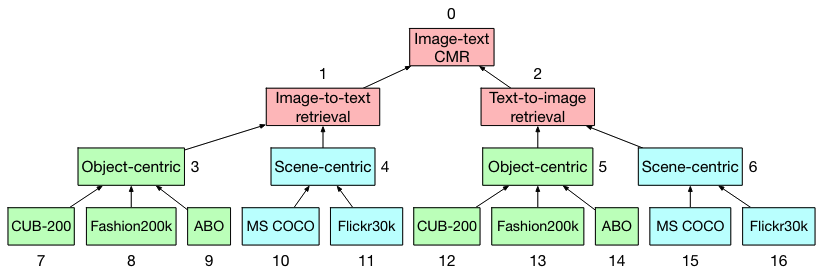
Mariya Hendriksen, Svitlana Vakulenko, Ernst Kuiper, Maarten de Rijke ECIR, 2023 arXiv / Github |

|
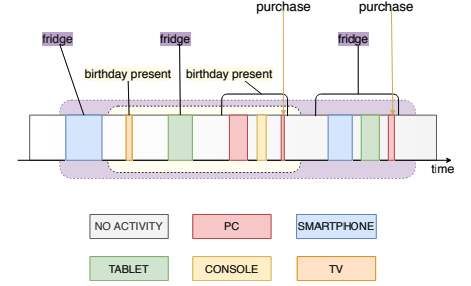
Mariya Hendriksen, Maurits Bleeker, Svitlana Vakulenko, Nanne van Noord, Maarten de Rijke ECIR, 2022 arXiv / Github |
|
Mariya Hendriksen, Ernst Kuiper, Pim Nauts, Sebastian Schelter, Maarten de Rijke SIGIR eCom, 2020 arXiv |
|
Build upon Jon Barron's template. |